ODI Series - Digging into ODI repository
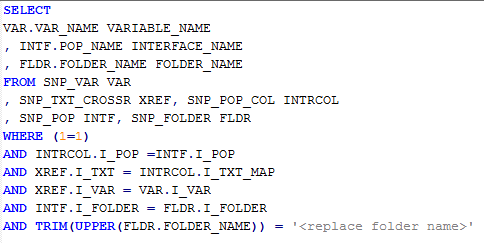
I believe it is no new situation for any ODI developer, where he/she had to go through a long list of ODI objects to identify their usage in interfaces or packages, LKMs /IKMs used within interfaces, variables and their usage, getting rid of unwanted objects, etc I had been in such a situation and wanted to keep a track of any such objects. I was able to beg, borrow, steal or develop SQL queries to query ODI work repository and following list of SQL queries can be used to put down a list of objects and their association Query 1: Variables Used in mappings Query 2: Table Names used as Source schema & Datastore Tabs Query 3: Interface Information Query 4: Interfaces not used in Packages --- Updated May 12th, 2014 --- Query 5: Procedures used in Packages Query 6: Procedures not used in Packages Query 7: Scheduling Information This scheduling information query fetches all scheduling information except repetition information ...



