EPM Integration Agent: Configuration tips
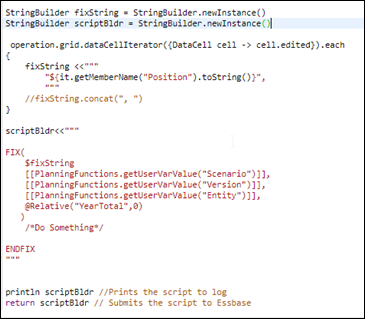
EPM Integration Agent was introduced sometime last year providing ability to connect to in-premise data sources. Though the tool has ability to connect to third party REST APIs via Groovy or Jython scripting but I assume the majority of the use cases would be to connect to relational databases, usually warehouses which had been used to feed data to various reporting and planning applications in the in-premise world. Unless clients move to any cloud based ERP, the data warehouses are going to stay for a while and the need to pull data too. Oracle provides connectivity for Oracle and MSSQL server by default, but what about other data sources? Other than scripting, if any data source offers SQL capability, we can essentially pull data. I had a recent experience connecting to Netezza database via Integration Agent and thought of sharing some quick tips I learnt during this exercise. Integration Agent Port Agent requires a port to communicate and by default it is 9090. Many organisatio...