I wanted to setup a Hyperion Planning 11.1.2.3 environment to try out new features under this release and thought of creating an application from the extract files of one of my app which I had used long back for training and proof of concept. I created a new Planning app shell similar to the app I was about to import.
Since 11.1.2.3 LCM offers ability to upload the LCM extract from shared services console in to File System directory (import_export by default), I followed these steps to upload the LCM extract.

On trying to open the app under the File System, it did not display any of the artifacts in the detail pane. Initially, I thought it could be some system error and restarted the services once. But that didn't help. On digging into the documentation, online forums and help from Nitesh, I realized that starting 11.1.2, LCM has undergone changes when it comes to importing and exporting of artifacts. Any artifact from 11.1.1.3 need to be first upgraded to 11.1.1.4 before migrating to 11.1.2. That is what was happening with this extract too. The SourceInfo.xml in the extract provide details about the LCM version used to create extract.
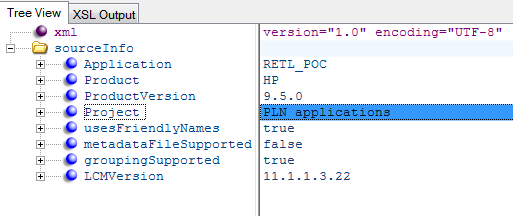
Few of the changes that can be easily identified:
- The console no longer has the option to 'Define Migration' while importing or exporting artifacts
- The LCM export in 11.1.2 stores the import and export definition XMLs.


Lets export the newly created app shell and compare the two extracts to find out how they differ. Lets name the LCM extract for the app shell as RETL_POC_APP.
- The 11.1.2.3 extract have the import.xml along with info and resource directories which did not exist in old extract. This is because old version allowed us to create migration definition file


- The listing.xml in 11.1.1.3 have a property "id" for folder tag which does not exist in the listing.xml from 11.1.2.3. But this field does not seems to have any unique value which may cause any problem during import. Lets ignore it as of now


There does not seem to be any major difference between the extracts. All I did is copied the Import.xml into the extract zip of 11.1.1.3 without changing any other xml, zip it and placed it back in the import_export directory. This time it worked !!!

Step 1: Select all artifacts and import
Selected all artifacts and started the import process. But it failed with errors while importing User Preferences.xml, Exchange Rates, Period, Planning Units and Security XMLs for groups and users.

Step 2: Deselect Standard Dimensions - Period & Year
Since the standard dimensions already exist in the target application, deselect the standard dimensions - Period & Year under Plan Type/PnL/Standard Dimensions. When ran the import again, it failed again

Step 3: Deselect User Preferences.xml and Security XMLs
The errors hold information that import process was unable to find groups and users. Since these users and groups does not exist in the Shared Services, these errors are valid. User Preferences.xml also hold information about users which should exist in Shared Services. This time import failed giving error for Planning Units.

On deselecting Planning Units.xml and importing it again leads to success. Voila !!!
All artifacts except security, Planning Units, User Preferences gets imported successfully. Though if we create the users and groups in shared services, Planning security would also get imported. I need to investigate more why Planning Units import failed even though the xml did not have any Planning Unit details.

Just to summarize,
- Providing the Import.xml (Migration definition file), LCM 11.1.2.3 was able to identify object to import.
- Users & Groups must exist in Shared Services to get migrated
- Standard Dimensions - Period & Year may not get imported as the number of years and period hierarchy may depend how we have defined them in target
As said earlier, these steps are an alternate option to import artifacts when we do not have configured environment from 11.1.1 release to follow upgrade path.
Hope this helps !!!









